Regression and
Survival Analysis
Simple

\[Y = \beta_0 + \beta_1 X + \epsilon\] Estimate \(\beta_0\), \(\beta_1\) by minimizing sum of squared errors
\(Y\) must be continuous & normally distributed
\(X\) can be continuous or categorical
If continuous: same as correlation analysis
If binary: same as t-test with equal variance
Bivariate Correlation
Use the Bivariate Correlation function to test linear association between two continuous variables.
- Analyze → Correlate → Bivariate…

- Move age and nodes into the Variables box
- Select Pearson as the correlation coefficient
- Choose Two-tailed test of significance


- Pearson correlation: r = -0.093
- p-value: < .001 → statistically significant
- Sample size: N = 1822
There is a weak negative, yet statistically significant, correlation between age and nodes.
Linear Regression: Predicting Nodes from Age
This regression estimates how age affects nodes (number of affected lymph nodes).
Go to Analyze → Regression → Linear…

Set nodes as the Dependent variable and age as the Independent(s) variable.


R = .093, R² = .009: Very weak linear relationship
Unstandardized coefficient for age = -0.028, p < .001
As age increases by 1 year, the number of nodes is expected to decrease by 0.028. The relationship is statistically significant but weak.
Linear Regression: Predicting Age from Nodes
This reverses the regression direction, predicting age from nodes.
Go to Analyze → Regression → Linear…
Set age as the Dependent variable and nodes as the Independent(s) variable.
.png)
- R = .093, R² = .009: Same strength as the previous model (symmetric)
- Unstandardized coefficient for nodes = -0.309, p < .001
Although both models are statistically significant (p < .001), the effect size (R² ≈ 0.009) is very small. This indicates that only about 0.9% of the variance in either variable is explained by the other.
Independent Samples T-test: Comparing Time by Sex
To compare the variable time between male and female groups using a t-test in SPSS:

- t = -0.317, df = 1856, p = 0.751
- No statistically significant difference in mean time between groups
We begin with a t-test because it is a simple, standard method for comparing group means when the predictor has only two levels. It provides the same result as regression but is more intuitive in this context.
Simple Linear Regression: Predicting Time from Sex
This analysis fits a linear regression model where time is predicted by sex.

Go to Analyze → Regression → Linear…
Set time as the Dependent variable and sex as the Independent(s) variable.


The regression result is consistent with the t-test:
There is no statistically significant association between sex and time.
Changing string into numeric in SPSS
The variable rx includes three treatment groups:
- 1 = Lev
- 2 = Lev+5FU - 3 = Obs (reference)

In SPSS, linear regression does not automatically treat string variables as categorical. To include a categorical variable like rx in a regression model, we must first convert it to numeric.
Use Automatic Recode if your original rx is a string variable. This assigns numeric values starting from 1: 1 = Lev, 2 = Lev+5FU, 3 = Obs
If it is a numeric variable, SPSS automatically chooses the lowest numeric value as the reference category.

This will assign numeric values starting from 1.
Now that
rx_newis numeric, SPSS will automatically create dummy variables when used in regression BUT it will use the lowest number as the reference group (e.g., 1 = Lev). To change the reference group (e.g., set 3 = Obs), go to Categorical… and select it manually.
Linear Regression with Categorical Variables (3 Groups)
Go to Transform → Compute Variable… To include a 3-group variable in regression, create two dummy variables:
- rx_lev = 1 if rx_new == 1, else 0
- rx_lev5fu = 1 if rx_new == 2, else 0


The reference group (row where all dummy variables are 0) is Obs, which is not coded explicitly.
Use Analyze → Regression → Linear

- Dependent variable:
time
- Independent variables:
rx_lev,rx_lev5fu

The constant is the mean for the Obs group. Coefficients show the difference from Obs: - rx_lev = difference between Lev and Obs
- rx_lev5fu = difference between Lev+5FU and Obs

Only rx_lev5fu shows a significant difference (p < .001)
Alternative: One-Way ANOVA
Use Analyze → Compare Means → One-Way ANOVA
to test whether any of the rx_new groups differ overall. - Dependent = time
- Factor = rx_new

- Options → Check Homogeneity of variance test (Levene’s test)

This gives an overall p-value for overall group comparison.

Including multiple variables
\[Y = \beta_0 + \beta_1 X_{1} + \beta_2 X_{2} + \cdots + \epsilon\]
- Interpretation of \(\beta_1\): When adjusting for \(X_2\), \(X_3\), etc., a one-unit increase in \(X_1\) leads to an increase of \(\beta_1\) in \(Y\).


Logistic regression
Used for Binary Outcomes: 0/1

\[ P(Y = 1) = \frac{\exp{(X)}}{1 + \exp{(X)}}\]
Finding Odds Ratio in SPSS
Go to Analyze → Regression → Binary Logistic... Move status to the Dependent box, sex, age, and rx_new into the Covariates box.

Click Categorical…
Select rx_new, move to Categorical Covariates
Set Reference Category to Last (e.g., Obs)

Exp(B) gives odds ratios

Time to event data
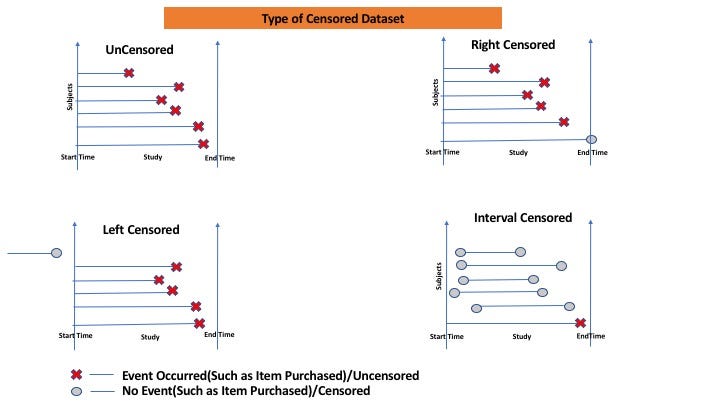
Most data are right-censored: the individual either died on day XX or survived up to day XX.
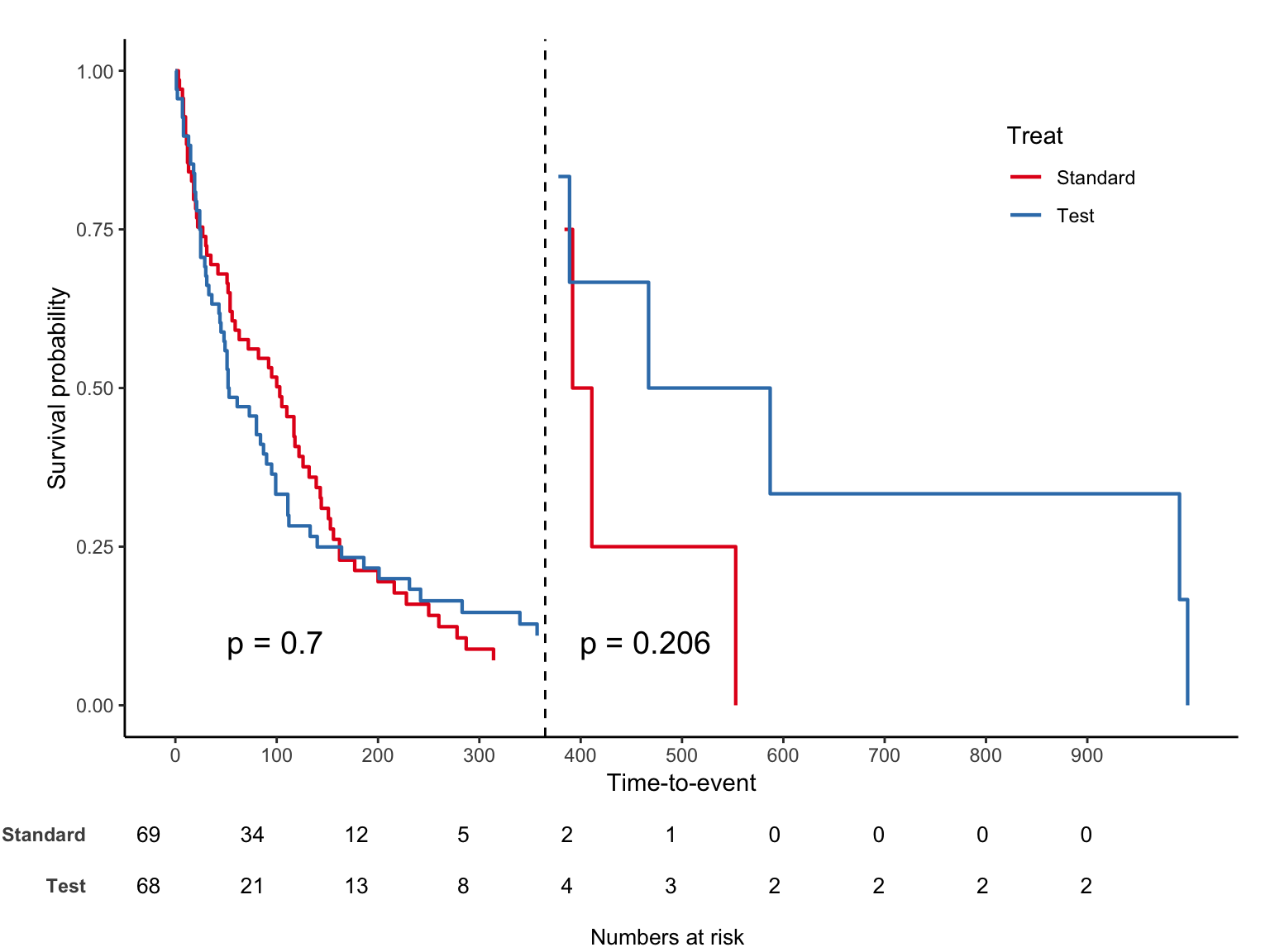
Kaplan-meier plot
In survival analysis, Table 1 typically presents baseline characteristics.
- It is usually accompanied by the log-rank test p-value to compare survival between groups.
Go to Analyze → Survival → Kaplan-Meier…
Set time as Time, status(1) as Status, rx_new as Factor

Click Options → Check:
- Survival table(s)
- Mean and median survival
- Survival plot

Click Compare Factor… → Check:
- Log rank
- Pooled over strata

Click OK to see:
- Kaplan–Meier plot with censored cases (+)
- Log-rank p-value comparing survival curves

Calculation:
Sort by time in ascending order
\[ \begin{aligned} P(t) &= \frac{\text{Survived at } t}{\text{At risk at } t} \quad \text{(Interval survival)} \\\\ S(t) &= S(t-1) \times P(t) \end{aligned} \]

Cox Regression in SPSS
- Go to Analyze → Survival → Cox Regression

- Set Time =
time, Status =status
Click Define Event, enter value = 1

Move
sex,age,rx_newto CovariatesClick Categorical, add
rx_new, set Reference Category to Last, click ChangeExp(B)= hazard ratio

Survival Analysis:
Proportional Hazards Assumption
Assumes a consistent trend: survival curves should not cross - No formal test for the assumption is strictly required — it can be checked visually.

Landmark-analysis
Analyze separately by dividing time into intervals.