딥러닝의 역사
이 글은 2014년 9월에 썼던 것을 HTML형식으로 재정리한 내용으로 최신지견이 아님을 감안하길 바란다. 슬라이드 버전은 여기에서 볼 수 있다.
서론
기계학습(Machine Learning)은 컴퓨터가 스스로 학습하여 예측모형을 개발하는 인공지능의 한 분야이며, 딥러닝(Deep Learning)은 인간의 신경망의 원리를 이용한 심층신경망(Deep Neural Network)이론을 이용한 기계학습방법이다. 딥러닝 기술은 이미 구글, 페이스북, 아마존 등 글로벌 IT기업들에서 광범위하게 이용되고 있는 기술이며 특히, 패턴인식이나 사진, 음성 등의 인식, 기계번역 등의 자연언어처리(Natural Language Processing)에 좋은 성능을 발휘하는 것으로 알려져 있는데, MIT가 2013년을 빛낼 10대 혁신기술 중 하나로 선정하고 가트너(Gartner, Inc.)가 2014 세계 IT 시장 10대 주요 예측기술로 언급하는 등 최근 가장 뜨거운 이슈가 되고 있다(동아일보, n.d.; Gartner, n.d.). 딥러닝이 기존의 통계학이나 다른 기계학습 방법과 다른 큰 차이점은 인간의 뇌를 기초로하여 설계되었다는 점이다. 인간은 컴퓨터가 아주 짧은 시간에 할 수 있는 계산도 쉽게 해낼 수 없는 반면, 컴퓨터는 인간이 쉽게 인지하는 사진이나 음성을 해석하지 못하는데 이는 인간의 뇌가 엄청난 수의 뉴런과 시냅스의 로 이루어져 있기 때문이다. 각각의 뉴런은 기능이 보잘것 없지만 수많은 뉴런들이 복잡하게 연결되어 병렬연산을 수행함으로서 컴퓨터가 하지 못하는 음성, 영상인식을 수월하게 할 수 있는 것이며 딥러닝은 이 수많은 뉴런과 시냅스의 병렬연산을 컴퓨터로 재현하는 방법인 것이다. 이것이 글로벌 IT기업들이 딥러닝을 주목하는 이유일 것이다. 이에 본 글에서는 인공신경망 이론의 역사부터 2014년 현재 상황까지를 간략히 리뷰해 보겠다.
딥러닝의 역사는 크게 3시기로 나뉘어지는데 1세대는 최초의 인경신공망인 퍼셉트론(Perceptron), 2세대는 다층(Multilayer) 퍼셉트론, 그리고 현재의 딥러닝을 3세대라고 할 수 있을 것이다.
1세대: Perceptron
인공신경망(Neural Network)의 기원은 1958년에 Rosenblatt가 제안한 퍼셉트론이 시작이라 할 수 있다[Rosenblatt (1958)}. \(n\)개의 input과 1개의 output에 대하여 각각의 input의 weight를 \(w_i\)라 한 후 퍼셉트론을 수식으로 나타내면 다음과 같다(Honkela, n.d.).
\[y=\varphi(\sum_{i=1}^n w_ix_i+b)\] (\(b\): bias, \(\varphi\): activation function(e.g: logistic or \(tanh\))
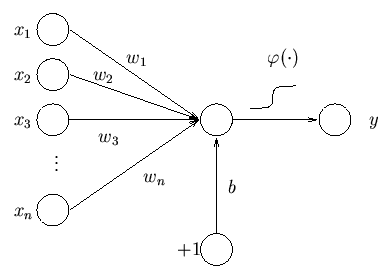
Concept of Perceptron
즉, \(n\)개의 input의 선형결합(Linear Combination)에 Activation 함수를 적용하여 0$$1 사이의 확률값으로 \(y\)값을 제공하는 것이며, 확률값으로 받은 후에는 편의에 따라 0를 기준으로 event냐 아니냐(1 VS -1)를 판단한다.
이것이 인공신경망 모형의 시작이다. 허나 이 모형은 아주 간단한 XOR problem마저 학습하지 못하는 등, 심각한 문제가 있는데(아래 그림) 이 때문에 한동안 발전없이 포류되게 된다(Hinton, n.d.).
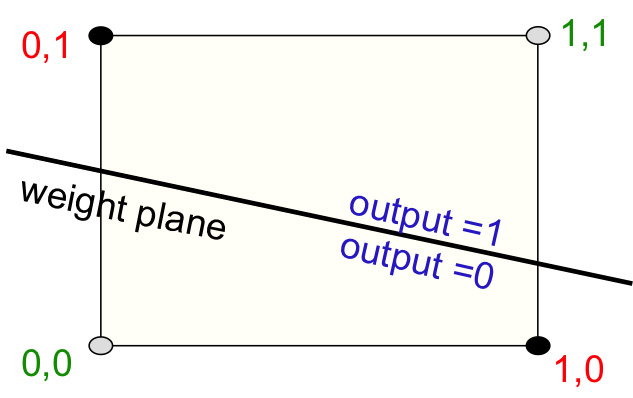
XOR problem in Perceptron
2세대: Multilayer Perceptron
XOR 같은 간단한 것도 학습하지 못하는 퍼셉트론의 단점을 해결하기 위한 방법은 의외로 단순하였는데 Input layer와 output layer사이에 하나 이상의 hidden layer를 추가하여 학습하는 것이 그것이며 이를 다층 퍼셉트론(Multilayer perceptron)이라 한다. 아래 그림을 보면 hidden layer가 증가할수록 분류력이 좋아지는 것을 확인할 수 있다.
허나 이 방법은 hidden layer의 갯수가 증가할수록 weight의 갯수도 계속 증가하게 되어 학습(Traning)이 어렵다는 단점이 있는데 Rumelhart등은 에러역전파알고리즘(Error Backpropagation Algorithm)을 개발하여 다층 퍼셉트론의 학습을 가능하게 하였다(Rumelhart, Hinton, and Williams 1985). 에러역전파알고리즘의 자세한 증명은 참고문헌이나 인터넷을 찾아보기 바라며 여기서는 기장 기초적인 예제인 음식 가격 맞추기로 설명해 보겠다.
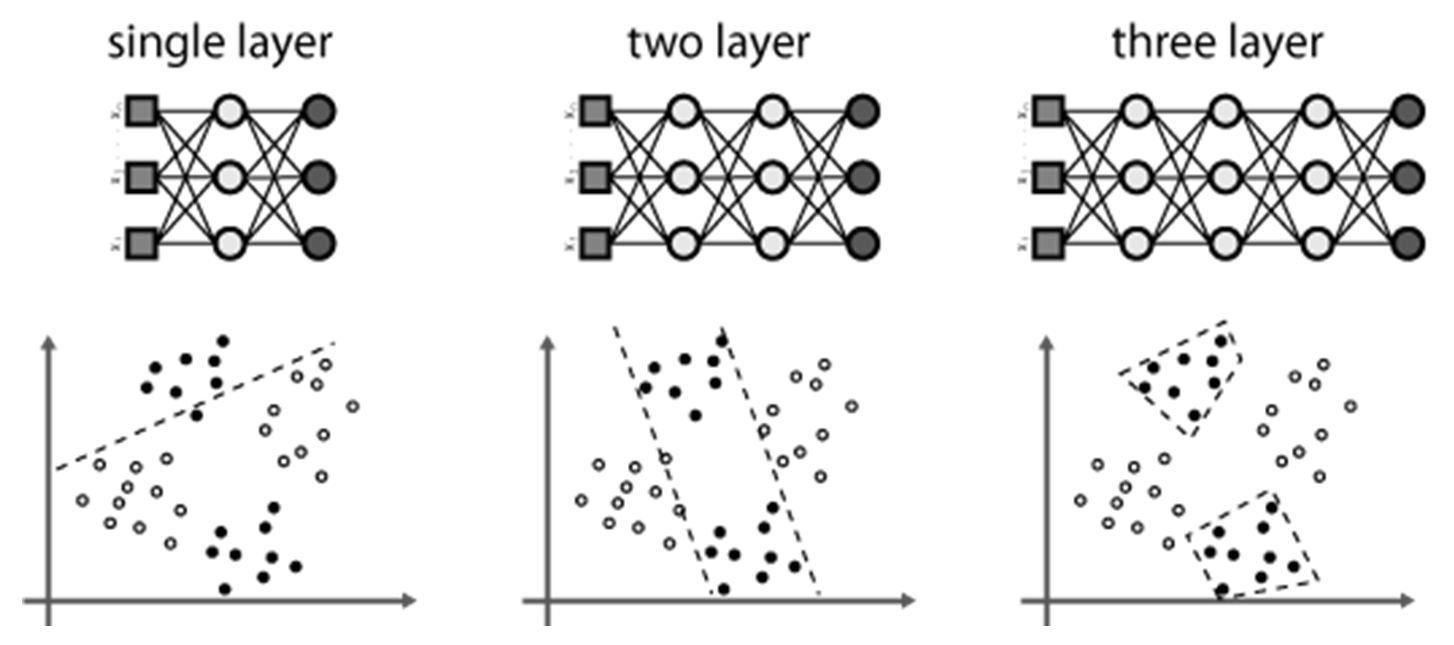
Multilayer Perceptron
예제: 음식의 가격 맞추기(Hinton, n.d.)
물고기(fish) 2개 과자(chip) 5개, 케첩(ketchup) 3개를 구입해서 가격(price)가 850원인 상황을 수식과 그림으로 나타내면 아래와 같다.
\[price = x_{fish}w_{fish} + x_{chips}w_{chips} + x_{ketchup}w_{ketchup}\]
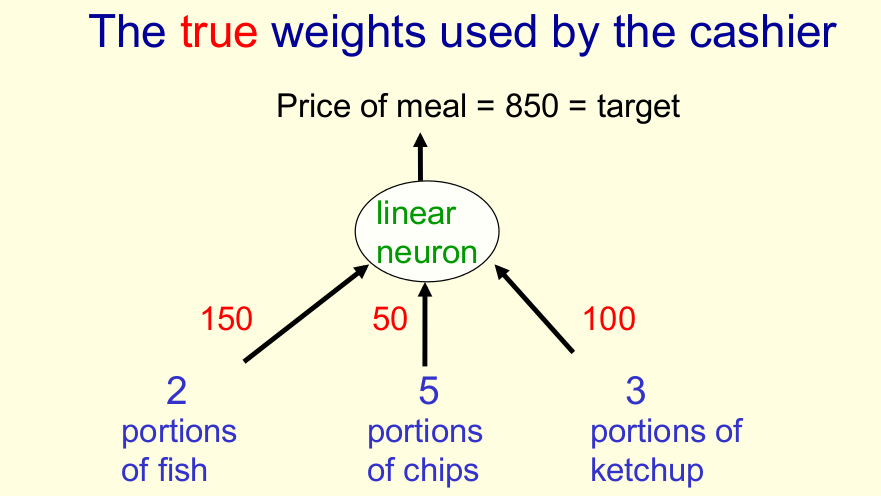
Example: Weight Estimation
이 때 가격을 나타내는 vector \(w\)를 \(w\)=\((w_{fish},w_{chips},w_{ketchup})\)과 같이 정의하고 error를 \(\frac{1}{2}(t-y)^2\)로 정의하면(\(y\): Estimation, \(t\): Real), 우리의 목표는 에러값을 최소로 하는 \(w\)를 추정하는 것이 된다. 다층퍼셉트론에서는 모수\(w_i\))들의 갯수가 너무 많아 회귀분석에서 쓰는 최소제곱추정량(Least Square Estimator), 최대가능도추정량(Maximum Likelihood Estimator)를 쓸 수 없고, 알고리즘을 이용하여 에러의 최소값에 가까워지게 해야 하는데 여기서 이용되는 것이 Gradient descent 방법이다. 이는 미분계수에 비례하여 모수를 수정한다는 것이 특징인데 이를 간단히 묘사하면 다음 그림과 같다(Han-Hsing, n.d.).
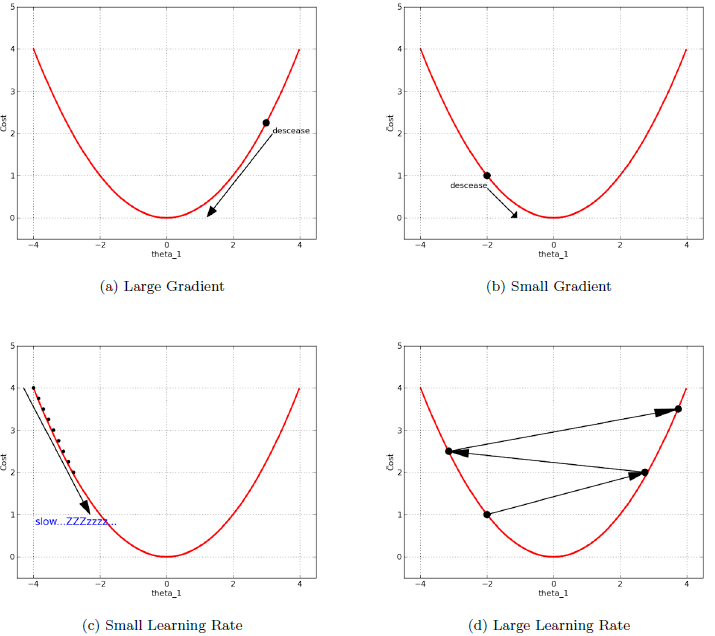
Example: Gradient Descent Algorithm
우리가 원하는 최소값일 때는 대부분 미분계수가 0일 때이므로 미분계수가 크면 크게 weight를 바꿔주고 미분계수가 작으면 작게 바꿔준다는 것이다. 또한 Learning rate를 결정할 수 있어서 얼마나 크게 바꿀지 대략적인 정도를 결정할 수도 있다.
이제 이를 적용하여 예제를 풀어보자, 초기값으로 고기와 과자 케첩이 모두 50원이라고 하면 물고기 2개, 과자 5개, 케첩 3개의 전체 가격은 500원이 된다. 한편 에러함수를 각각 \(w_i\)에 대해 미분하면,
\[\frac{\partial E}{\partial w_i}= \frac{\partial y}{\partial w_i} \frac{dE}{dy}\] 가 되고 \(E=\frac{1}{2}(t-y)^2\), \(y=x_{fish}w_{fish} + x_{chips}w_{chips} + x_{ketchup}w_{ketchup}\)을 대입하면
\[\frac{\partial E}{\partial w_i}= \frac{\partial y}{\partial w_i} \frac{dE}{dy}= - x_i(t-y)\] 가 되며 Learning rate를 감안한 \(w_i\)의 변화량은
\[\Delta w_i= -\epsilon \frac{\partial E}{\partial w_i}= \epsilon x_i(t-y)\] 이 된다.
대입해보면 \(t\)=850, \(y\)=500, \(w_{fish}=w_{chips}=w_{ketchup}\)=50 이고 간단한 계산을 위해 \(\epsilon=\frac{1}{35}\)로 하면 \(\Delta w_{fish}\)=20, \(\Delta w_{chips}\)=50, \(\Delta w_{chips}\)=30이 되고 이를 적용하면 다시 구해진 weight는 순서대로 70, 100, 80이 되며 이를 토대로 추정한 가격은 880이 된다. 이제 880과 850을 가지고 위의 과정을 계속 반복하면 참값에 가까운 값을 얻을 수 있을 것이다.
지금 설명한 것은 가장 기초적인 알고리즘을 설명한 것이며 실제 오류역전파 알고리즘은 초기 weight를 토대로 다층 hidden layer를 거쳐서 하나의 예측값을 구하고 그 예측값과 실제값의 차이를 토대로 역으로 weight들을 수정해 나가게 된다(아래 그림)(Kim, n.d.).
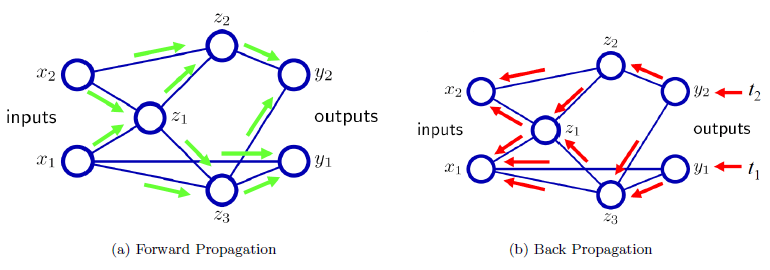
Backpropagation algorithm
에러역전파알고리즘으로 다층퍼셉트론을 학습할 수 있게 되었으나 이것을 실제로 사람들이 이용하기에는 많은 어려움이 따랐는데 그 이유들은 다음과 같다.
- 수많은 Labeled data가 필요하다.
- 학습을 하면 할수록 성능이 떨어진다(Vanishing gradient problem).
- Overfitting problem
- Local minima에 빠질 가능성
하나씩 살펴보자. 추정해야 하는 모수가 많기 때문에 데이터가 많이 필요하고 그 중에서도 labeled data가 많이 필요하다. 허나 우리가 갖고 있는 데이터는 unlabeled data가 훨씬 많으며 실제 인간의 뇌의 학습 중 많은 부분이 unlabeled data를 이용한 Unsupervised Learning이며, 적은 양의 labeled data로 다층퍼셉트론을 학습하면 종종 hidden layer가 1개인 경우보다 성능이 떨어지는 경우를 관찰할 수 있으며 이것이 과적합(Overfitting)의 예시이다.
다음으로 Activation function을 살펴보면 logistic function이든 \(tanh\) function이든 가운데 부분보다 양 끝이 현저히 기울기의 변화가 작은 것을 발견할 수 있다(아래 그림).
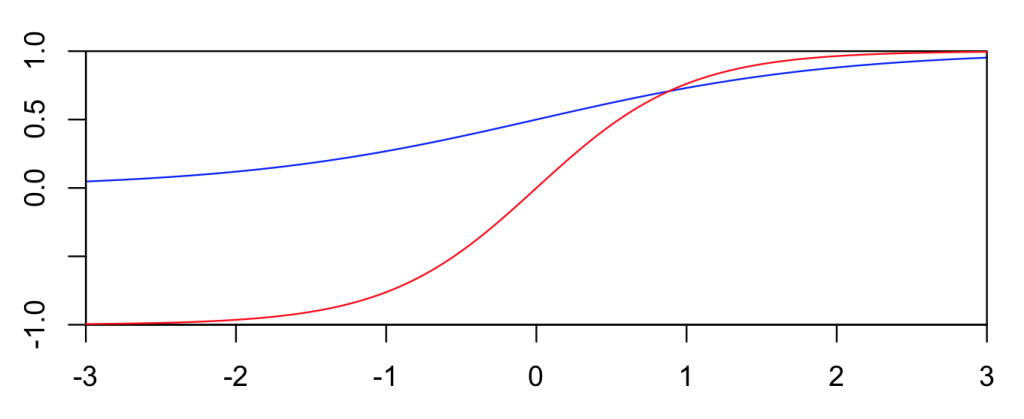
Sigmoid functions
때문에 학습이 진행될수록 급속도로 기울기아 0에 가까워져서 나중에는 거의 Gradient descent가 일어나지 않아 학습이 되지 않는 단점이 있다(Bengio, Simard, and Frasconi 1994).
마지막으로 최소제곱추정량이나 최대가능도추정량등 직접적으로 최소값을 구하는 방법을 이용하지 못하고 알고리즘을 이용하여 최소값에 가까워지게 했기 때문에 학습에서 나온 최소값이 과연 진짜 최소값(Global minima)인가? 국소 최소값(Local minima)는 아닌가..에 대한 의문점이 풀리지 않게 된다. 시작점을 어떻게 두느냐에 따라 Local minima에 빠질 수도 있기 때문이다(아래 그림)(Kim, n.d.).
Global and Local Minima
이런 문제점들 때문에 실제로 Neural Network은 지지벡터머신(Support Vector Machine)등에 밀려 2000년 초까지 제대로 활용되지 못하였다.
3세대: Unsupervised Learning - Boltzmann Machine
앞서 언급한 단점들 때문에 인공신경망 이론이 잘 이용되지 못하다가, 2006년 볼츠만 머신을 이용한 학습방법이 재조명되면서 인공신경망 이론이 다시 학계의 주목을 받게 되었는데 이 볼츠만 머신의 핵심 아이디어는 바로 Unsupervised Learning, 즉 label이 없는 데이터로 미리 충분한 학습을 한다는 것이며 그 후에 앞에 나온 역전파알고리즘 등을 통해 기존의 supervised learning을 수행한다[Smolensky (1986);Hinton and Salakhutdinov (2006)}. 아래 그림에 대략적인 묘사가 표현되어 있는데 아기들은 단어나 음, 문장의 뜻을 전혀 모르는 상태로 학습을 시작하게 되고 음소(phoneme), 단어(word), 문장(sentence)순으로 Unsupervised learning을 수행하게 되며 그 후에 정답을 가지고 supervised learning을 수행하게 된다(Kim, n.d.).
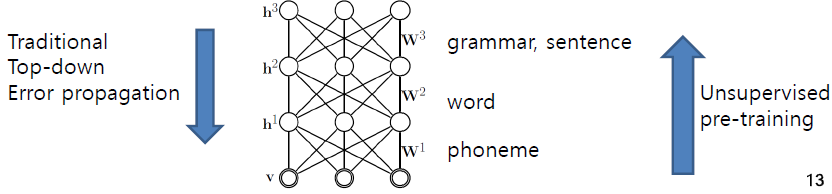
Description of Unsupervised Learning
이런 방법을 통해 앞서 언급한 다중 퍼셉트론의 단점들이 많이 해결되는데, Unlabeled data를 이용할 수 있고 이를 이용해 unsupervised pre-training을 수행함으로서 vanishing gradient problem, overfitting problem이 극복될 수 있으며, pre-training이 올바른 초기값 선정에도 도움을 주어 local minima problem도 해결할 수 있을 것이라 여겨지고 있다[Bengio (2009)}. 이에 본 글에서는 가장 대표적인 방법인 Deep Belief Network(DBN)과 이를 수행하기 위해 필요한 Restrict Boltzmann Machine(RBM)에 대하여 간단히 설명하기로 하겠다.
Restricted Boltzmann Machine(RBM)
볼츠만 머신은 visible layer와 1개의 hidden layer로 이루어진 방향이 없는 그래프(undirected graph)로 이루어져 있다. 이것의 특징은 Energy based model이라는 점인데 Energy based model이라는 것은 어떤 상태가 나올 확률밀도 함수를 에너지의 형태로 나타내겠다는 것이며 visible unit의 벡터를 \(v\), hidden unit의 벡터를 \(h\)라 하면(\(v\),\(h\): binary vector- 0 or 1) 볼츠만 머신의 그래프와 확률밀도함수는 아래와 같다(LeCun et al. 2006; LeCun and Huang 2005).
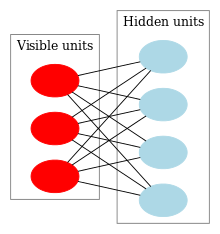
Diagram of a Restricted Boltzmann(Wikipedia, n.d.)
\[P(v,h)=\frac{1}{Z}\exp^{-E(v,h)}\]
볼츠만 머신의 그림을 보면 \(v\)끼리는 선이 연결되어 있지 않고 \(h\)끼리도 마찬가지인데 이것이 Restricted의 의미이며 이 조건이 없으면 그냥 Boltmann Machine이며 RBM형태의 그래프를 이분그래프(bipartite graph)라 한다. 그냥 Boltzmann Machine은 너무 복잡해서 학습이 어려워 그 대안으로 나온 것이 RBM인 것이다. 한편 수식을 보면 그래프의 에너지 상태가 낮을수록 확률이 작아지는 것을 알 수 있는데 이 가정은 물리학의 열역학 2법칙을 연상시킨다. 이제 RBM의 Energy function을 살펴보면
\[E(v,h)= -\sum_i a_i v_i - \sum_j b_j h_j -\sum_i \sum_j h_j w_{i,j} v_i=-a^{\mathrm{T}} v - b^{\mathrm{T}} h -h^{\mathrm{T}} W v\] (\(a_i\): offset of visible variable, \(b_j\): offset of hidden variable, \(w_{i,j}\): weight between \(v_i\) and \(h_j\))
에너지에 대한 수식에서 눈여겨 보아야 할 부분이 \(\sum_j h_j w_{i,j} v_i\)인데, \(v_i\), \(h_j\)가 1인 곳에 weight가 클수록 에너지함수 값이 작아지고 결과적으로 확률밀도함수의 값이 높아진다. 이는 인간의 시냅스에서 일어나는 일과 비슷한데, 같이 켜지는 곳이 시냅스로 연결될 가능성이 높기 때문이다(아래 그림).
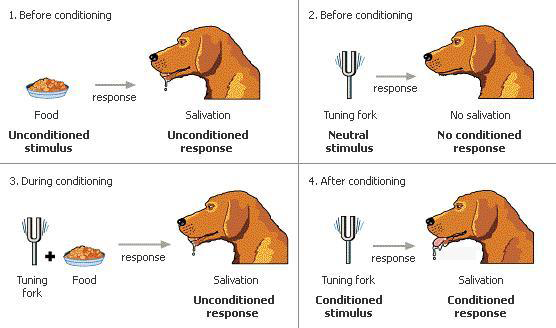
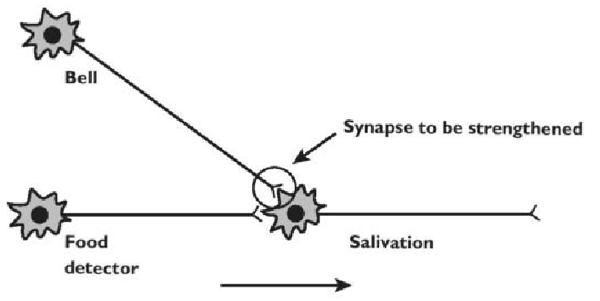
Hebb’s Law(Muehlhauser, n.d.,kimjunmoppt)
이제 우리가 원하는 것은 \(P(v)=\sum_h P(v,h)\) 의 최댓값을 구하는 것인데 RBM은 이분그래프로 \(v\)끼리, \(h\)끼리는 전부 독립이므로
\[P(v|h) = \prod_{i=1}^m P(v_i|h)\] \[P(h|v) = \prod_{j=1}^n P(h_j|v)\]
로 간단히 분리할 수 있으며, 이에 따른 individual activation probabilities는
\[p(h_j=1|v) = \sigma \left(b_j + \sum_{i=1}^m w_{i,j} v_i \right)\] \[p(v_i=1|h) = \sigma \left(a_i + \sum_{j=1}^n w_{i,j} h_j \right)\]
로 표현할 수 있다(\(\sigma\): activation function). 이 장점을 이용하여 Gibbs sampling을 쓰면서 weight를 수정해 나가면 간단히 \(logP(v)\)의 최댓값과 그때의 weight들을 구할 수 있는데 이 방법에 대해 간략히 알아보겠다.
Training RBM
기본적인 아이디어는 앞서 퍼셉트론에서 언급한 Gradient descent 방법과 일치한다. 기울기(미분계수)에 비례해서 감소시키면 결국 minima에 도달할 것이라는 아이디어인데 RBM에서는 \(logP(v)\)의 최댓값과 그때의 \(w\), \(a\) , \(b\) 들을 구하는 것이 목적이므로 Gradient descent의 반대 방향으로 알고리즘을 쓰면 된다(Gradient ascent). 한편 \(logP(v)\)를 다시 표현하면
\[logP(v)=log(\sum_{h} \frac{\exp^{-E(v,h)}}{Z})=log(\sum_h \exp^{-E(v,h)})-logZ=log(\sum_h \exp^{-E(v,h)})-log(\sum_{v,h} \exp^{-E(v,h)})\]
과 같고 이를 미분하면
\[\frac{\partial logP(v)}{\partial \theta}=-\frac{1}{\sum_h \exp^{-E(v,h)}} \sum_h \exp^{-E(v,h)}\frac{\partial E(v,h)}{\partial \theta}+\frac{1}{\sum_{v,h} \exp^{-E(v,h)}} \sum_{v,h} \exp^{-E(v,h)}\frac{\partial E(v,h)}{\partial \theta} \]
\[= -\sum_{h} p(h\mid v) \frac{\partial E(v,h)}{\partial \theta} + \sum_{v,h} p(h,v)\frac{\partial E(v,h)}{\partial \theta}\]
과 같으며 맨 아래의 식을 살펴보면 first term은 \(\frac{\partial E(v,h)}{\partial \theta}\)를 \(p(h|v)\)를 가지고 평균을 낸 것이고, second term은 같은 것을 \(p(h,v)\)의 확률분포를 기반으로 평균을 낸 것이라 할 수 있다. 이 들은 모두 Gibbs sampling을 이용하여 sampling할 수 있는데 여기서는 일반적인 Gibbs sampling과는 약간 다른 Contrastive Divergence(CD-\(k\)) 방법을 쓰게 된다. CD-\(k\)의 과정을 간단히 설명하면 처음엔 training sample에서 \(v\)를 random sampling하고 그 \(v\)를 대상으로 \(p(h|v)\) 함수를 이용하여 first term을 해결하며, 그 다음으로는 계속 이어서 \(k\)-1번의 횟수동안 \(p(h|v)\), \(p(v|h)\) 함수를 이용하여 sampling을 수행하여 나온 \(v^{(k)}\)를 이용하여 second term을 해결한다는 것이다. \(k\)는 보통 1으로도 충분하다고 알려져 있으며 위의 과정을 를 수행하여 나온 값을 기반으로 \(w\), \(a\), \(b\)를 업데이트 하고 같은 과정을 반복해나가면 되는 것이다. 이를 pseudocode로 요약하면 아래 그림과 같다.

Contrastive Divergence(CD-\(k\))(Fischer and Igel 2012)
Deep Belief Network(DBN)
DBN은 간략히 말하면 RBM을 여러 층으로 쌓은 것인데 아래 그림에 대략적인 묘사가 되어 있다.
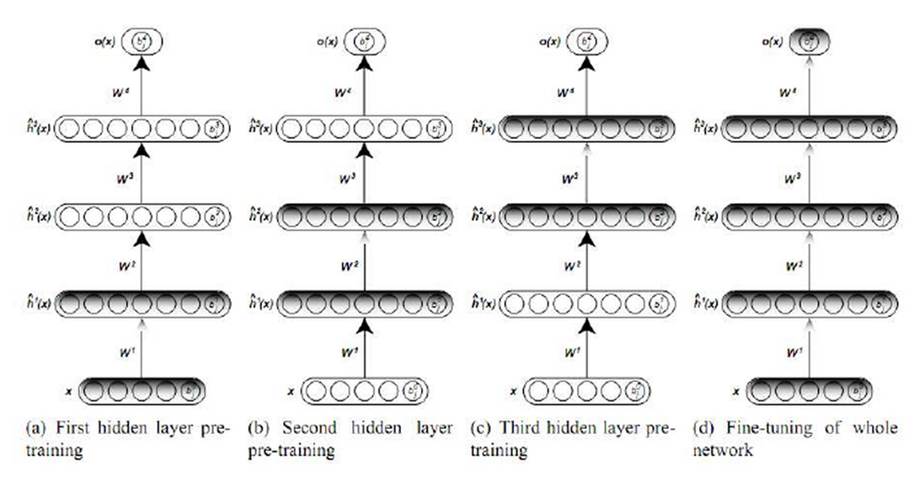
Deep Belief Network(Larochelle, n.d.)
즉 RBM을 여러 층을 두어 학습하고 마지막으로 기존의 오류역전파알고리즘을 이용하여 튜닝(Fine tuning)하는 것이다(G. Hinton, Osindero, and Teh 2006; Hinton 2009; Bengio 2009). 이는 위에 예시로 든 아기가 언어를 학습하는 방식인 음소(phoneme), 단어(word), 문장(sentence)순의 Unsupervised training과 그 후의 supervised learning을 반영하는 모형이라 할 수 있다.
DBN은 각각의 과정에서 확률적으로 hidden layer들의 값을 생성하게 되는데 이를 역으로 진행하면 정답을 토대로 input을 생성할 수도 있다. 이를 generative model이라 하는데 Hinton교수의 홈페이지에 손으로 쓴 숫자인식에 대한 예제가 나와 있으니 참고하기 바란다.
기타
이외에도 locally connected convolution layer를 이용한 Convolutional RBM, 텍스트와 이미지를 동시에 학습할 수 있는 Multimodal Learning에 유용한 Deep Boltzmann Machine(DBM) 등이 있는데 이것들은 참고문헌을 참고하길 바란다(Lee et al. 2009; Salakhutdinov and Hinton 2009).
3세대: Supervised Learning - Rectified linear unit (ReLU), Dropout
RBM을 이용한 Unsupervised learning을 이용하게 되면서 다층퍼셉트론의 약점이 많은 부분 극복되었다. Unlabeled data를 사용할 수 있게 되었고 이를 충분히 활용하여 overfitting issue, vanishing gradient문제가 해결되었고 pre-training이 좋은 시작점을 제공하여 local minima 문제도 해결되는 것처럼 보였다. 한편, 언급된 다층퍼셉트론의 약점을 그냥 Supervised Learning에서 해법을 찾으려는 최근의 노력들이 있었고 그 결과로 지금까지 나온 대표적인 아이디어가 Rectified linear unit(ReLU), Dropout이다. 본 섹션에서는 이 두 방법에 대해 간단히 소개하도록 하겠다.
Rectified linear unit (ReLU)
Vanishing gradient 즉, 학습을 할수록 weight의 기울기가 0에 급속도로 가까워 지는 것이 다층퍼셉트론(multilayer perceptron)에서 학습이 어려운 이유 중 하나였다. 이는 activation함수의 모양에서 기인하는데 아까 나왔던 sigmoid함수를 다시 살펴보자.
Sigmoid functions
다시 살펴보면 logistic function이든 \(tanh\)함수이든 가운데 부분만 기울기가 가파르고 양끝으로 갈수록 기울기가 급속도로 0에 가까워지는 것을 볼 수 있고 이것이 vanishing gradient의 실제이다. 2010년과 2011년에 걸쳐 이를 극복하기 위한 아이디어가 제시되었는데 그것이 바로 Rectified linear unit(ReLU)이다. 이름에서 직관적으로 느낄 수 있듯이 이는 \(x\)가 0이상일 때는 선형증가하는 함수이며 0미만일 때는 모두 0인 함수인데, 아래 그림에서 볼 수 있듯이 0보다만 크면 항상 기울기가 1로 일정해 기울기가 감소하는 경우가 없어 학습이 용이하며 실제로 이것이 기존의 방법보다 학습성능이 좋고 pre-training의 필요성을 없애준다고 알려져 있다(Nair and Hinton 2010; Glorot, Bordes, and Bengio 2011).
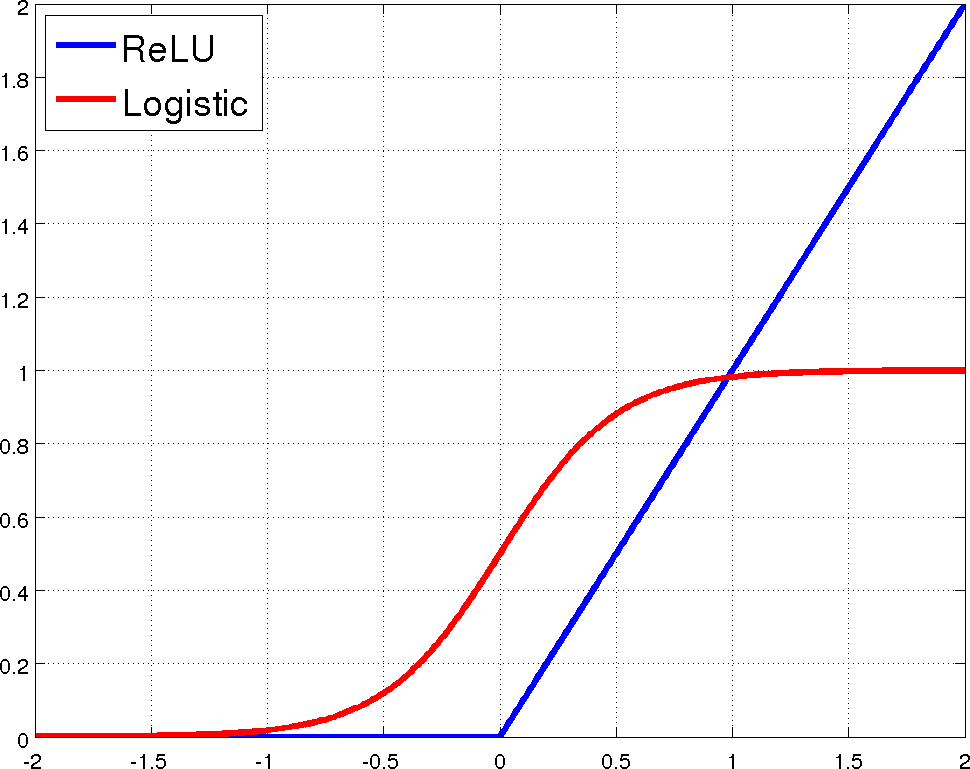
The proposed non-linearity, ReLU, and the standard neural network non-linearity, logistic(Zeiler et al. 2013)
DropOut
Labeled data의 부족 및 그로 인한 overfitting 즉, hidden layer들은 많은데 labeled data의 수가 적은 것도 다층퍼셉트론 학습이 어려운 이유 중 하나였다. 이에 Hinton교수는 2012년에 DropOut이라는 방법을 제안하는데 이는 기본적으로 여러개의 모형을 합쳐서 새로운 모형을 만드는 Ensemble 모형과 유사하다(Hinton et al. 2012). Training example을 학습할 때 마다 모든 hidden unit을 50%의 확률로 끄는(DropOut)것인데 이를 비유하자면 회사에서 모든 팀이 모든 일을 함께 하는 것보다 팀별로 분담해서 일을 한 후 그것을 통합하는 것이 더 효율적으로 업무를 수행할 수 있는 것과 비슷하다고 할 수 있다. 즉, 각 데이터를 학습할 때마다 hidden unit의 절반만 써서 결론적으로 그 학습결과를 합치면 기존의 학습방법보다 좋은 성능을 보인다는 것이다. 2013년에는 이 아이디어를 확장하여 DropConnect라는 방법이 제안되었는데, 이것은 hidden unit을 끄는 대신 hidden unit과의 연결을 50%의 확률로 꺼서 학습하는 점이 DropOut과의 차이점이다(아래 그림)(Wan et al. 2013).
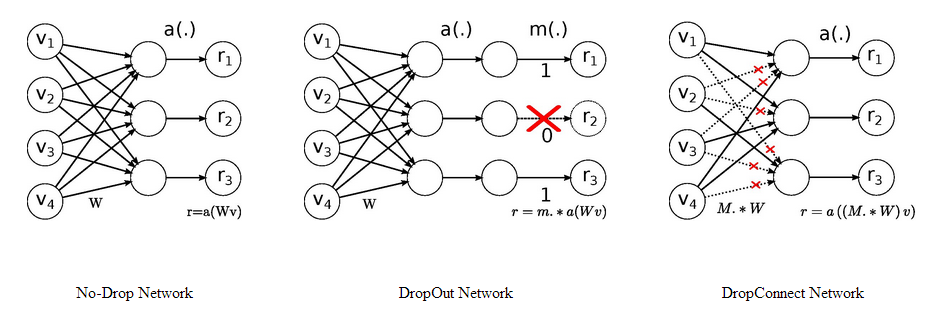
Description of DropOut & DropConnect(Wan, n.d.)
실제로 DropOut과 DropConnect의 성능이 그렇지 않은 경우보다 우수함이 알려져 있다(Wan et al. 2013).
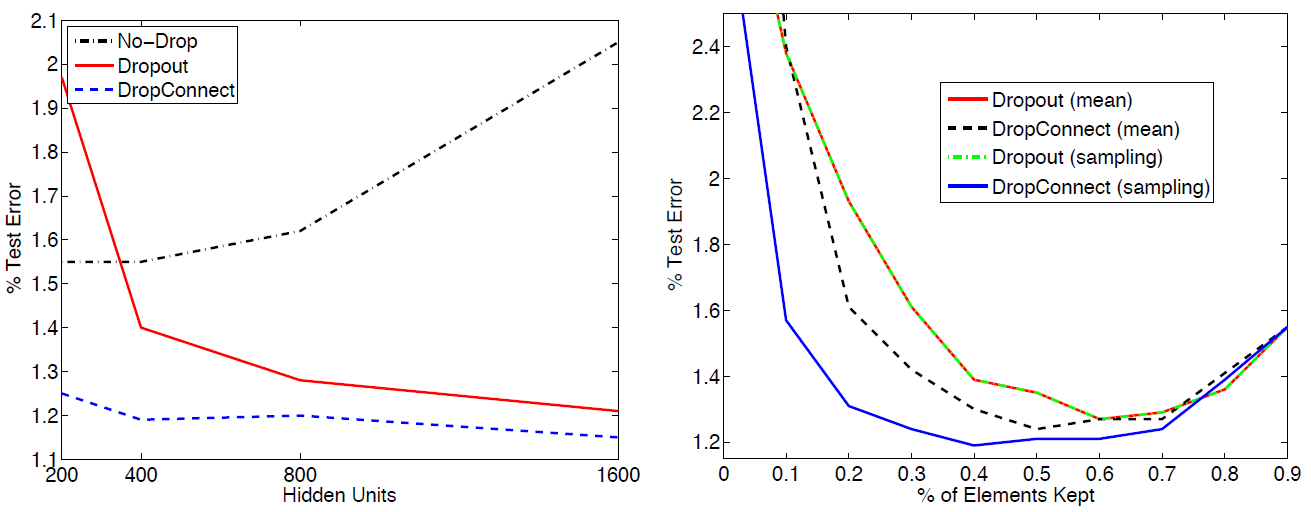
Using the MNIST dataset, in a) Ability of Dropout and DropConnect to prevent overfitting as the size of the 2 fully connected layers increase. b) Varying the drop-rate in a 400-400 network shows near optimal performance around the \(p\) = 0.5(Wan et al. 2013)
Local minima issue
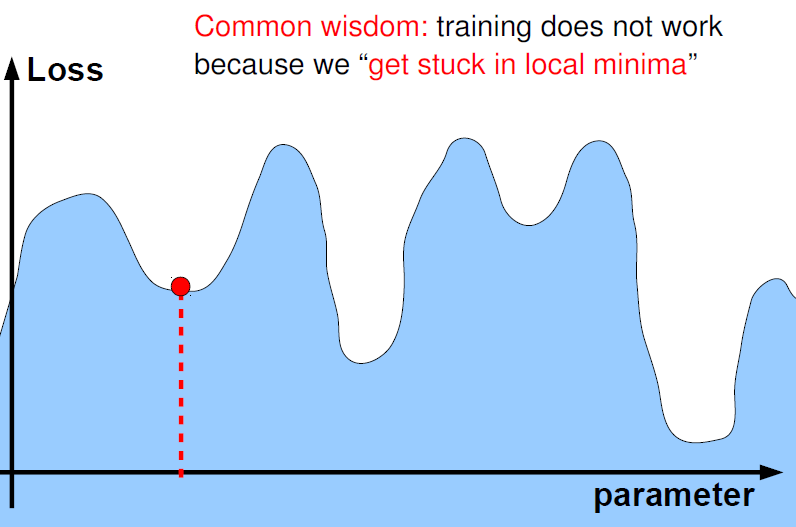
우리가 구한 에러의 최소값이 실제 Global minima인가.. local minima에 빠지는 것은 아닌가.. 라는 문제도 오랫동안 다층퍼셉트론에서의 이슈였는데 현재의 공감대는 High dimension and non-convex optimization에서는 대부분의 local minima들의 값이 비슷비슷할 것이며 따라서 local minima나 global minima나 크게 차이가 없을 것이고 너무 이 문제에 신경쓸 필요가 없다는 점이다(아래 그림)(Ranzato, n.d.).
Local minima when high dimension and non-convex optimization(Ranzato, n.d.)
수많은 차원에서 차원마다 local minima이기는 쉽지 않다고 직관적으로 이해할 수 있다.
마지막: 딥러닝 요약
1950년대 퍼셉트론(perceptron)에서 시작된 인공신경망 연구는 1980년대 오류역전파알고리즘(Error Backpropagation Algorithm)으로 다층퍼셉트론(Multilayer perceptron)을 학습할 수 있게 되면서 발전을 이루었다. 허나 Gradient vanishing, labeled data의 부족, overfitting, local minima issue 등이 잘 해결되지 못해 2000년대 초까지 인공신경망 연구는 답보를 이루고 있는데, 2006년부터 볼츠만머신을 이용한 Unsupervised Learning인 Restricted Boltzmann Machine(RBM), Deep Belief Network(DBN), Deep Boltzmann Machine(DBM), Convolutional Deep Belief Network 등이 개발되면서 unlabeled data를 이용하여 pre-training을 수행할 수 있게 되어 위에 언급된 다층퍼셉트론의 한계점이 극복되었다. 2010년부터는 빅데이터를 적극적으로 이용함으로서 수많은 labeled data를 사용할 수 있게 되었고, Rectified linear unit (ReLU), DropOut, DropConnect 등의 발견으로 vanishing gradient문제와 overfitting issue를 해결하여 아예 Supervised learning이 가능하게 되었으며, local minima issue도 High dimension non-convex optimization에서는 별로 중요한 부분이 아니라는 공감대가 확장되고 있다.
참고문헌
Bengio, Yoshua. 2009. “Learning Deep Architectures for Ai.” Foundations and Trends in Machine Learning 2 (1). Now Publishers Inc.: 1–127.
Bengio, Yoshua, Patrice Simard, and Paolo Frasconi. 1994. “Learning Long-Term Dependencies with Gradient Descent Is Difficult.” Neural Networks, IEEE Transactions on 5 (2). IEEE: 157–66.
Fischer, Asja, and Christian Igel. 2012. “An Introduction to Restricted Boltzmann Machines.” In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, 14–36. Springer.
Gartner, Inc. n.d. “가트너, 2014 세계 It 시장 10대 주요 예측 발표.” http://www.acrofan.com/ko-kr/commerce/news/20131013/00000015.
Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. 2011. “Deep Sparse Rectifier Networks.” In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. JMLR W&CP Volume, 15:315–23.
Han-Hsing, Tu. n.d. “[ML, Python] Gradient Descent Algorithm (Revision 2).” http://hhtucode.blogspot.kr/2013/04/ml-gradient-descent-algorithm.html.
Hinton, Geoffrey. n.d. “Coursera: Neural Networks for Machine Learning.” https://class.coursera.org/neuralnets-2012-001.
Hinton, Geoffrey E. 2009. “Deep Belief Networks.” Scholarpedia 4 (5): 5947.
Hinton, Geoffrey E, and Ruslan R Salakhutdinov. 2006. “Reducing the Dimensionality of Data with Neural Networks.” Science 313 (5786). American Association for the Advancement of Science: 504–7.
Hinton, Geoffrey E, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. 2012. “Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors.” arXiv Preprint arXiv:1207.0580.
Hinton, Geoffrey, Simon Osindero, and Yee-Whye Teh. 2006. “A Fast Learning Algorithm for Deep Belief Nets.” Neural Computation 18 (7). MIT Press: 1527–54.
Honkela, Antti. n.d. “Multilayer Perceptrons.” https://www.hiit.fi/u/ahonkela/dippa/node41.html.
Kim, Junmo. n.d. “2014 패턴인식 및 기계학습 여름학교.” http://prml.yonsei.ac.kr/.
Larochelle, Hugo. n.d. “Deep Learning.” http://www.dmi.usherb.ca/~larocheh/projects_deep_learning.html.
LeCun, Yann, Sumit Chopra, Raia Hadsell, M Ranzato, and F Huang. 2006. “A Tutorial on Energy-Based Learning.” Predicting Structured Data.
LeCun, Yann, and F Huang. 2005. “Loss Functions for Discriminative Training of Energybased Models.” In. AIStats.
Lee, Honglak, Roger Grosse, Rajesh Ranganath, and Andrew Y Ng. 2009. “Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations.” In Proceedings of the 26th Annual International Conference on Machine Learning, 609–16. ACM.
Muehlhauser, Luke. n.d. “A Crash Course in the Neuroscience of Human Motivation.” http://lesswrong.com/lw/71x/a_crash_course_in_the_neuroscience_of_human/.
Nair, Vinod, and Geoffrey E Hinton. 2010. “Rectified Linear Units Improve Restricted Boltzmann Machines.” In Proceedings of the 27th International Conference on Machine Learning (Icml-10), 807–14.
Ranzato, Marc’Aurelio. n.d. “Deep Learning for Vision: Tricks of the Trade.” www.cs.toronto.edu/~ranzato.
Rosenblatt, Frank. 1958. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review 65 (6). American Psychological Association: 386.
Rumelhart, David E, Geoffrey E Hinton, and Ronald J Williams. 1985. “Learning Internal Representations by Error Propagation.” DTIC Document.
Salakhutdinov, Ruslan, and Geoffrey E Hinton. 2009. “Deep Boltzmann Machines.” In International Conference on Artificial Intelligence and Statistics, 448–55.
Smolensky, Paul. 1986. “Information Processing in Dynamical Systems: Foundations of Harmony Theory.” Department of Computer Science, University of Colorado, Boulder.
Wan, Li. n.d. “Regularization of Neural Networks Using Dropconnect.” http://cs.nyu.edu/~wanli/dropc/.
Wan, Li, Matthew Zeiler, Sixin Zhang, Yann L Cun, and Rob Fergus. 2013. “Regularization of Neural Networks Using Dropconnect.” In Proceedings of the 30th International Conference on Machine Learning (Icml-13), 1058–66.
Wikipedia. n.d. “Wikepedia.” http://en.wikipedia.org/wiki/Restricted_Boltzmann_machine.
Zeiler, Matthew D, M Ranzato, Rajat Monga, M Mao, K Yang, Quoc Viet Le, Patrick Nguyen, et al. 2013. “On Rectified Linear Units for Speech Processing.” In Acoustics, Speech and Signal Processing (Icassp), 2013 Ieee International Conference on, 3517–21. IEEE.
동아일보. n.d. “MIT,올해의 10대 혁신기술 선정.” http://news.donga.com/3/all/20130426/54713529/1.
Copyright ©2016 Jinseob Kim